FUNgi(第一版)工作日志
前情提要
FUNgi 是由友人 Y 设计的互动装置,是一个形似树桩的毛线织物,里面填充棉花。针织部分包括一些导电纱线,在受到挤压或拉伸时会改变电特性,可以由单片机检测到,发出对应的声音。
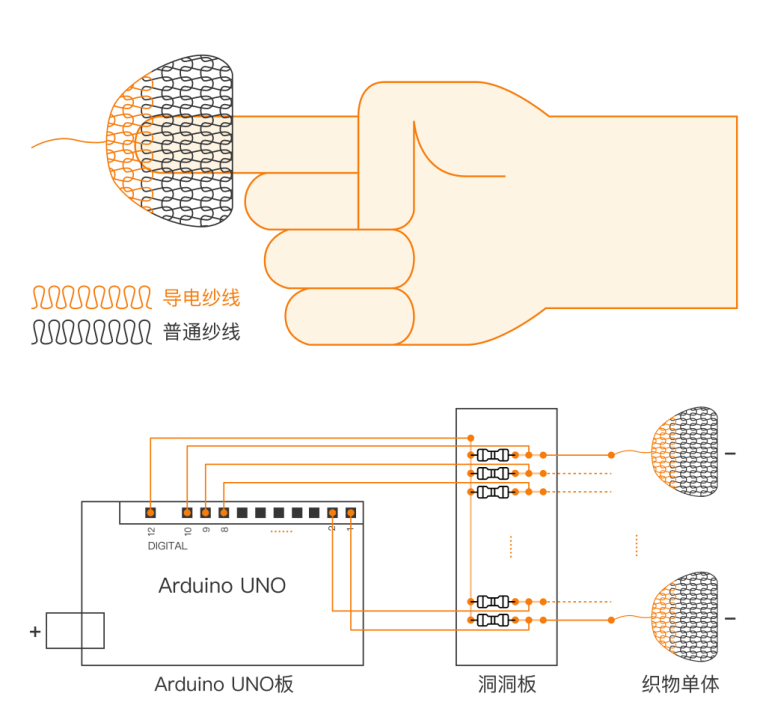
之前是毕业设计课题,但由于时间缘故未能完善互动功能,只通过蜂鸣器发出声音,且并非所有互动区域都能出声。此次主要工作是协助完成技术实现部分,参加一周后的一场小展览。
Day -8
看到了整个装置,非常可爱,要是家里有一个肯定天天抱着。
确认技术原理后补齐了相关知识。
电容传感的原理是,为了测量两个引脚之间的电容,将其中一端(发送引脚)的电压拉高,再持续检测另一端(接收引脚)的电压是否变高;记录其中的时间差。
注:具体而言,由于 RC 串联网络的阶跃响应是 ,所以接收引脚的反应时间约为 ,因此所探测到的时间差与电容成正比。根据此式也可估算出具体的电容值,只不过在大部分场景中只关心比例与变化量。- 扬声器不可以用蜂鸣器代替,后者的频率响应有限,主要为方波设计,声音信号容易失真。
从 Arduino 单片机输出扬声器时由于引脚输出功率不足(5 V × 20 mA = 0.1 W),所以需要一个放大器。参考 Arduino 网站上的教程,使用一个倍率设置为 200 的 LM386 放大器芯片,连接若干电阻与电容形成放大电路。

(来源:上述链接页面 / LM386 数据手册)
左侧与地之间的 10 kΩ 可变电阻相当于将输入电压乘以一个倍率(可变电阻的英语 potentiometer 其实就是“测量电势”的意思!)。此电阻与其串联的 10 µF 形成高通滤波器,过滤输入的直流偏置,截止频率 f_0 = 1/RC = 1/(10 kΩ × 10 µF) = 10 rad/s = 1.6 Hz。集成芯片 1 号与 8 号引脚之间的 10 µF 电容用于改变放大倍率(参考数据手册)。右侧元件的作用暂时没搞明白。
注:实际上,右侧接地的串联 RC 是一个特定于此芯片的去耦网络,按照数据手册第 9 章的说明添加即可;末尾的电容与扬声器则串联成为 RC 网络,于是在扬声器两端形成高通滤波。数据手册给出的 250 µF 电容值适用于耳机、音响的较大阻抗,如果使用 8 Ω 的小喇叭,需要按照截止频率 1/(2πRC) = 20 Hz 重新计算电容,得到电容值约为 1000 µF。对这一点的忽视确实在后续造成了音质的问题,详见下文。
购入所需元器件;由于所有电容两侧电压方向均固定,可任意选用有极性电容。0.05 µF 与 250 µF 都没有找到精确值的元件,分别用 47 nF(0.047 µF)与 220 µF 代替。电容元件的容差普遍较大,所以总归不太会有问题。
Day -6
拿到了友人工作室里的 Arduino 开发板,有 Uno 和 Leonardo 等不同种类。打印出电容传感器读数,看到用手触碰时读数会变大。
明天的任务是为所有引出的线贴好标签,并且确定触发检测算法及传感阈值。另外,需要试验多个区域同时按下时传感数值的模式。
Day -5
意识到需要确认不同开发板上的传感器数值是否一致。由于当前所用程序库的传感数值基于处理器指令周期,理论上基频相同的处理器所得的值应当一致,不同处理器所得的值应相差常数倍。需要确认这一点。
写了一个程序,读出传感器读数;发现噪声有些大,改成连续取 5 次原始采样值,再反复 5 次并取中位数,便稳定许多。用顶上九个凸起的区域测试,看上去数值稳定了许多,而且同时按下两个时的变化也非常明显。如果有一个被触发的传感器数值为 200 而其余传感器数值可忽略的话,采样 25 次的耗时就是 200 × 25 / 310 = 16 ms,即采样频率 60 Hz。虽然还有不少优化空间(比如滑动平均,还有之前说的一次性检查所有引脚),但或许够用。顺便,发现 Uno 板的 0 和 1 号引脚似乎不好用,传感一直超时,只好从 2 号引脚开始。
注:实际上是由于 0 号和 1 号引脚用于 USART 通信的缘故。
之前调研声音合成的时候看到过一个程序库 Mozzi,然而它要求至少以 64 Hz 刷新音频缓冲,但是我们的原理并不能保证实时性,单次传感采样的耗时上限很大(数秒)。因此可能需要放弃 Mozzi,改用自行调用时钟中断。另外,由于传感采样高度依赖 CPU 忙循环,因此即使单次采样也需要在期间关闭中断(虽然不知道为什么 CapacitiveSensor 库的实现没有关闭……可能会影响一些准确度?),如果读数为 1000,则持续约 1000 / 310 = 3 ms,这个值对于音频应用来说仍然相当大;有可能需要考虑改写传感逻辑,在等待期间允许中断,计时改为 micros() 或者开启一个没有 prescaler 的时钟。
准备写一个程序用来在电脑上可视化观察串口数据。然后发现 Arduino IDE 自带一个 Serial Plotter,无敌好用,那还自己写啥呀。不过 Plotter 工具只支持八个值,需要额外在文字窗口里观察一下第九个数值。
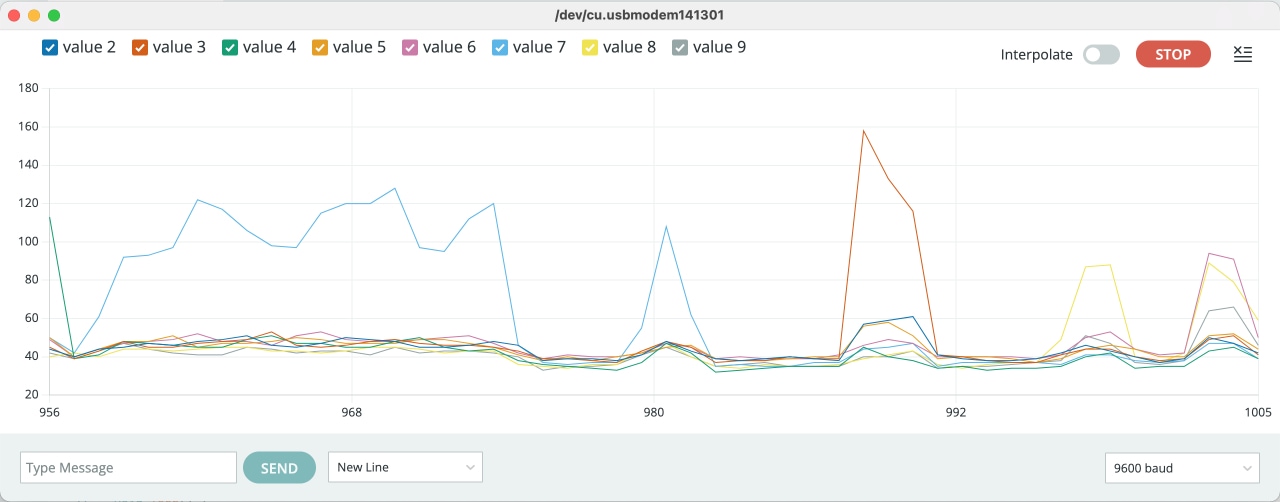
由于自己并不了解人体与装置接地的物理模型,需要依靠实验来确认。将装置从架子上搬到地面上重新测试,观察到传感器数值基本没有变化。因此可能变化模式受环境的影响并不大。
用标签贴纸捆好引脚并标注顺序,测试传感区域与引脚之间的对应。顶上拍按区有一个电极没有接触,怀疑是内部的线松动,一时无法拆开,只能放弃之。

左上起:拍按区、斗状区、揉捏区、凸条区
至于引脚的固定方式,确实可以按照颜色编码顺序,但究极偷懒的办法还是直接用标签捆起来……

有了相对稳定的读数,传感算法则是水到渠成:将一段时间内的最低值作为基准,观察读数是否连续大于基准值即可。具体逻辑:为每个传感电极维护一个基准电容值(即最低值),根据原始值动态更新;然后将原始读数值与之作差,即得到过滤的读数。简化的程序如下。
// 更新基准值,与原始读数取小者 if (base > result) base = result; // 原始读数与基准值作差,得到过滤读数 result -= base; // 每隔一段时间尝试增加基准值,以适应环境变化的情形 // 如果环境没有变化,增加量会在下一次刷新时抹去 if (lastBaseIncrement + 1000 < millis()) { base++; lastBaseIncrement = millis(); }
试验过程中发现偶然的低值可能导致读数值长期偏大。改成每次循环至多允许基准值减少 1,这样便能长期稳定地判定触发了。以下是今天的完整程序。
| 传感器数值输出 | SensorInspect_0512.ino(1.7 KiB) |
Day -4
基准值在每次循环中的减少量上限改成了 5,这样反应更快一些。发现昨天遗漏了踢打区的电极顺序标注,补之。

之前购置的元件都已到齐,在面包板上搭建扬声器放大电路。

没有 10 Ω 电阻,暂时用拥有的最小电阻 220 Ω 代替;这样与 0.05 µF 结合的低通滤波器截止频率是 14 kHz,只是勉强足够。考虑之后去机器人社团问问。
向 A0 引脚写入 250 Hz 方波信号,测试可以出声,然而只是滋滋声。没有示波器,用万用表检测,意识到 A0 输出仍然是 PWM —— Arduino Uno 并没有板上 DAC,有 DAC 的是 Arduino Zero;所以只能控制逻辑电平的占空比,没法像 Zero 的 A0 引脚那样输出任意模拟值。之前玩过树莓派就以为最简单的小板子都是 Zero……总之,按照我们现有的设备,必须加上外置 DAC。
在机器人社团拿到了 8.2 Ω 电阻,但是没有 DAC。线上购买可能来不及送达,或许只能明天早上去附近的电子元器件商城找了。关于选型,考虑并行 8 位 DAC080x 或者串行 12 位 DAC8512 (SPI)/ MCP4x21(SPI)/ MCP4725(I²C);如果采样率为 16 kHz,那么后者要求约 200 kHz 的 GPIO 频率,即不低于 2.5 µs 的反应时间。
迷茫,看了会 DAC8512 和 MCP48x1 的数据手册,供电和接地都有那么多讲究,要把尖刺都过滤掉。这么说难道之前的滋滋声也是因为输入端只加了高通没加低通?DAC080x 看上去好麻烦,不仅要单独的参考电压,而且 Arduino 那可怜的引脚数未必能腾出 8 路并行输出,可能不太考虑了。可能优先找 DAC8512 和 MCP4821 这样串行接口的吧。话说为什么 V_s 是电源电压,V_SS 就是接地电压啊,长得那么像,好吓人。
Day -3
早早醒来睡不着,研究一些知识。
时钟中断。处理器主频是 16 MHz,因此将 prescaler 设为 1024 可以获得 16 kHz 的中断频率。查阅 Uno 和 Leonardo 板上的控制器(分别是 ATmega328P 和ATmega32u4)数据手册,确认 Timer/Counter 的行为是兼容的。
采用 Timer/Counter1 溢出触发中断,撰写程序如下。每隔 16384 次中断翻转一次状态,间隔应为一秒。
void setup() { // 清空 CS12:0,然后重新写入 0b101 TCCR1B = (TCCR1B & ~((1 << CS12) | (1 << CS11) | (1 << CS10))) | ((1 << CS12) | (0 << CS11) | (1 << CS10)); TIMSK1 |= (1 << TOIE1); pinMode(13, OUTPUT); } ISR(TIMER1_OVF_vect) { static int timerCount = 0, pinStatus = 0; if ((timerCount = ((timerCount + 1) & 16383)) == 0) digitalWrite(13, (pinStatus ^= 1)); } void loop() { }
发现 CS12:0 = 0b101 时中断频率很低,约为 30 Hz,而 = 0b001 时大约是 31 kHz。所以 clk_I/O 是 31 kHz 吗?放弃挣扎直接向 ChatGPT 提问,它说溢出是每 65536 个时钟周期发生一次。顿悟了,果然自己还是笨乎乎的。明白原因之后就不那么担心了,直接这样达到 31 kHz 的采样率就很不错。
……但是仍然不对。如果是每 65536 个时钟周期一次的话,那么中断频率应该是 16 MHz / 65536 = 244 Hz 而不是 16 kHz。一顿翻找,在 ATmega32P 数据手册的 Table 15-5 看到 WGM12:0 也会影响计数器上限值,也即影响溢出发生的频率;有可能 Arduino 驱动程序为 WGM12:0 初始化的值不为 0(未查证)。将 WGM12:0 全部设为 0,频率确实下降到约 244 Hz。例如,以下程序的闪烁周期略长于 1 秒。
void setup() { TCCR1A = 0; // WGM12:0 置零 TCCR1B = (0 << CS12) | (0 << CS11) | (1 << CS10); TIMSK1 |= (1 << TOIE1); pinMode(13, OUTPUT); } ISR(TIMER1_OVF_vect) { static int timerCount = 0, pinStatus = 0; if ((timerCount = ((timerCount + 1) & 255)) == 0) digitalWrite(13, (pinStatus ^= 1)); } void loop() { }
因此设置 WGM12:0 = 0b001,采用 8 位 phase correct PWM 模式(计数器到达 8 位上限 0xFF 后下降至 0,完成一次循环并触发溢出),即可获得 16 MHz / (256 × 2) = 31.25 kHz 的中断频率(事实上这似乎也是之前的默认值)。可以将其作为音频采样率的基础。
将 setup() 开头改为 TCCR1A = (1 << WGM10); 即可。GPT 还是败了呢。
关于放大器。重新研究了一下 LM386 数据手册,放大 200 倍的确实是电压,只不过在达到供电电压的时候会裁切。一看 6.1 节赫然写着最大输入 ±0.4 V,这么说昨天折腾那一通该不会把元件弄坏了吧……另外,真的很需要一根单独的电源。昨天那样直接从 Arduino 5V 引脚接出线来给放大器供电居然没有坏掉真是奇迹。但是为什么要把增益设成 200 呢,20 不是反而能充分利用 DAC 的精度吗,不理解。
以及,一个真正“开放”的平台应该很容易调试才对,像教程里这样引一个库然后“just works”其实只是方便制作而不是理解。我至今不知道 WavePlayer 类的输出电压是多少。
等到大约上班的时候就出发去元器件商城,然而似乎周末不开门,遗憾离场。
下午回到学校,继续工作。复制了一份 CapacitiveSensor 库中的程序逻辑,将基于 CPU 周期的计时改为基于 micros()。原本自行实现的校正算法实现存在问题:由于使用 int 整型来存储 lastBaseIncrement“上次增加基准值的时刻”,而 ATmega 上的 int 是 16 位,因此 32768 毫秒之后基准值便不再每秒自增,于是基准值过低的问题再次出现。已修复。目前的采样率符合预期,闲置时约为 60 Hz,触发时约为 20~40 Hz。
增加滑动平均算法,每组采样 11 次、保留三组历史采样,这样一来在节省时间的同时将纳入考虑的采样次数增加到 33 次;同时改为取排序后中间三分之一数值的均值作为读数,稳定性进一步提升。
| 计时机制、滑动平均、触发判定 | Trigger_0514.ino(7.2 KiB) |
针对不同互动区调整阈值,也试着编写了不同的算法,效果还不错,虽然并不是最灵敏,不过也许已经接近目前传感方案的极限了。
| 触发测试——踢打区 | Trigger_Test_Kick.mp4(1.2 MiB, 00:07, 1440x810) |
| 触发测试——斗状区 | Trigger_Test_Pick.mp4(1.5 MiB, 00:11, 1440x810) |
| 触发测试——揉捏区 | Trigger_Test_Squeeze.mp4(1.2 MiB, 00:08, 1440x810) |
剩余程序存储空间约 25 KiB,需要在其中实现音频合成算法。由于暂时无法继续电路方面的工作,计划先在电脑上编写合成器算法,最后再转移到 Arduino 上调试。
考虑一下是否可以将声音直接按采样存储下来。最近新出的 QOA 格式看上去很适合我们的场景,但它对 16 kHz 单声道仍然大约要求 50 kbps,如果使用采样,至多只能存储 4 s。还是需要更巧妙的合成算法啦,不排除要手写 Fourier 级数……
Day -2
再次跑去市场。昨天去的地方有了人,但是他们推荐我去对面的商城,说那边多一些——所以昨天是跑错地方了啊!
询问是否有 5 V 驱动的串行 12-bit DAC,得知这里只支持自己选型然后按型号一个个问。感觉有点影响效率,但或许电子元器件市场就是这样子吧!
DAC8512 一片要 100 多……于是想着换成 MCP4821。业务员在电脑上敲了一会儿就开始打电话跟对面讲粤语问有没有 MCP4821(用粤语念英文字母好神奇!),一分钟后又打了个普通话的电话。最后的答复是整个市场上只有五块直插(读作:万一坏掉了就没救了x),而且单价要 55 元,比 Mouser 上的价格贵一倍,还需要等到饭点结束。被业务员推荐用贴片加转换板,贴片库存倒是很多,价格至少也和 Mouser 上的直插一样(27),算是可以接受了。我其实不太懂怎么用贴片(SOP-8),业务员十分热心地教我说只要焊上转换板就可以了,还给了我好多排针。买了 8 片,开销合计 (25 + 3) × 8 = 224。
今天外面真是超级热,最高气温有 35℃,不远处的汽车、栏杆、绿化,看上去都颤颤巍巍的。
下午把传感程序搬到 Leonardo 板上试了一下,工作正常。改为 micros() 计时之后也不需要按照板的特性调整传感数值了,不过都是 16 MHz 的 AVR 的话好像也没什么区别。
完成第一块 MCP4821 分线板的焊接,在面包板上搭起测试电路。其实自己不太懂焊接,只好边做边拿着万用表使劲“滴滴”。

开始编写程序。查阅 MCP4821 数据手册,Figure 1-1 是时序图(注:16 MHz 主频相当于每条指令 62.5 ns,16 kHz 采样率相当于每个采样 62.5 µs),Section 5 是 SPI 接口说明。
有一个驱动库可以直接使用,很方便,不用自己啃数据手册了。将 DAC 的输出直接连到 A0 端口,读出数值。程序如下。
| 驱动 DAC 并检查其输出端电压 | DAC_0515.ino(439 B) |
上述程序实际上就是切换高低输出电压,再通过 analogRead(A0) 读回。串口打印 0 0、1 812,其中 812 是 DAC 输出 4.095 V 与参考电压 5 V 的比值缩放到 0~1023 范围内的结果,在误差允许范围内正确。
开始将放大器 LM386 加入整个电路,焊接在洞洞板上。暂时还未继续处理声音合成的问题。

目前的电路原理图如下。Arduino 左侧留出的引脚仅作示意,可连接十个传感电极;实际上传感电极引出的杜邦线均直接插入板上的基座。
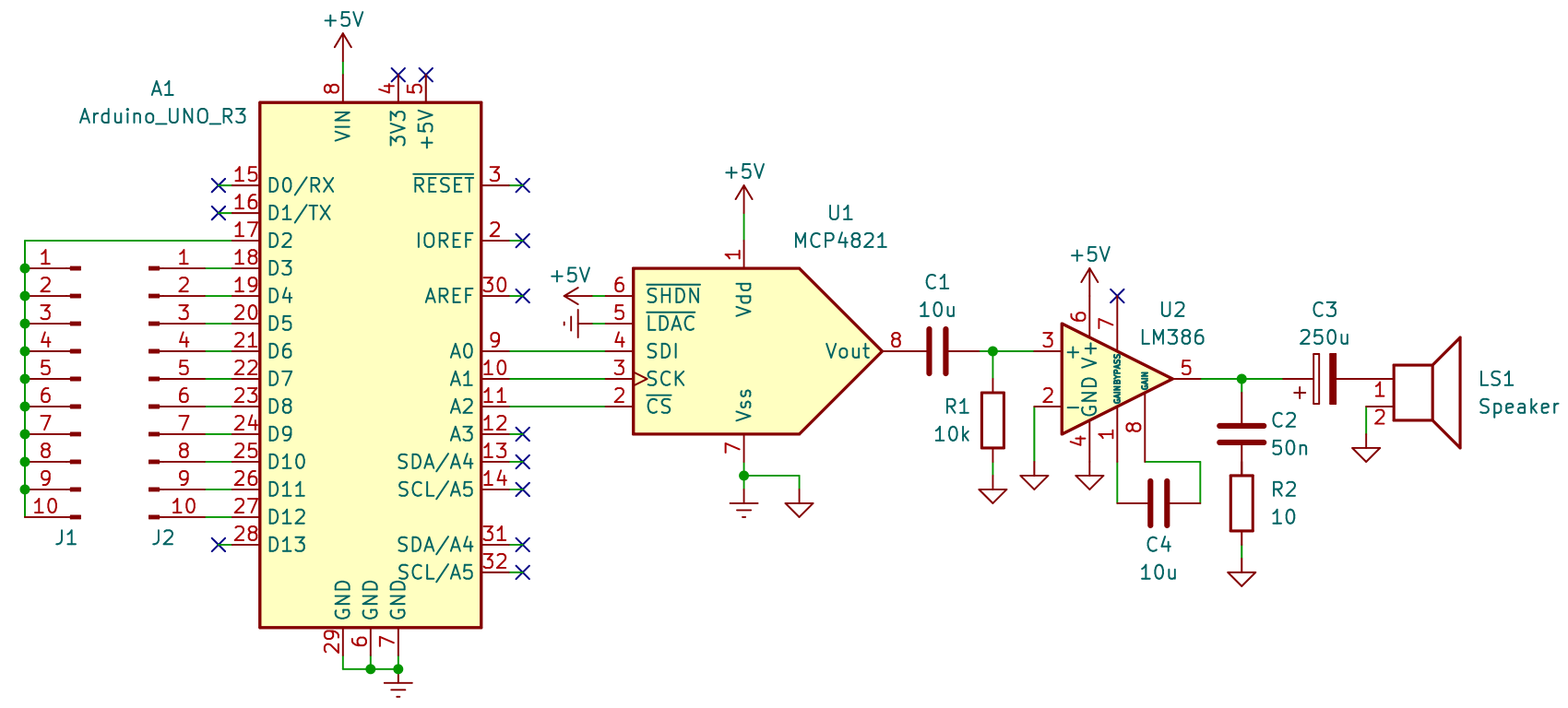
由于没抽出时间改程序,所以还没有开始测试电路,只好寄希望于设计、焊接都不出现失误,到最后一次性接通。做软件时喜欢分成小段边写边测,这样的工作习惯碰到电路就只能抓瞎了,唉。
目前的方案是七个区域各自都需要一块控制器与电路板,所以焊接工作还需要重复很多遍。以及,用于研究声音合成的时间可能非常有限了。不知道来不来得及。
Day -1
今天下午有一节课,友人提出自己翘课当电焊工,让我正常去课堂,晚上再腾出时间专心解决程序上的问题。于是一下午过去,数块电路板的焊接工作全部完成。
傍晚终于开始编写输出声音的程序。先尝试方波。
ISR(TIMER1_OVF_vect) { static int timerCount = 0; timerCount++; if (timerCount % 24 == 0) McpDac.analogWrite(((timerCount / 24) & 1) * 6); }
总算是发出了第一个声音。
| 嘟——(不用调大音量) | Sound.mp4(581 KiB, 00:08, 960x540) |
音量太大,向 DAC 中写入 6 时开始有声音,而 10 时已经达到相当充足的音量,这样一来有效位深只有 2 位,不可接受。因此拆去 LM386 第 1、8 引脚间的电容(上文原理图中 C4),将放大倍率从 200 改回 20。
采样率遇到瓶颈。32 kHz 采样率意味着每个采样只有 500 个指令周期,而且 AVR 没有硬件浮点单元,如果直接使用 sinf 计算很容易超时。将时钟换用 CTC 模式、降低到 4 kHz,并且换用 16 位定点计算,再加上预先计算查找表,时间才足够充裕。仍需注意 int 的长度只有 16 位,而涉及到 32 位乘法计算的整数是长整形——字面值末尾需要加 L。
| 基础波形输出 | Oscillator_0516.ino(1.2 KiB) |
测试完成方波、正弦波、三角波、锯齿波等基础波形。然而有效位深还是非常有限:在 DAC 的分辨率为 1 mV(增益 = 1)时,输出 50 mV peak(35 mV RMS)的音量就已经相当大,这样有效位深仍然只有 6 位。不过,既然 1 kHz 正弦波的一个周期都只剩下 8 个采样,似乎位深也没有那么重要。
考虑换用缓冲区以降低每个采样的平均耗时,64 个采样的缓冲区相当于 4 kHz 采样率下的 16 ms 延迟,可以接受。但是要异步填充也很难实现,毕竟目前传感的做法还是忙循环,而一次传感采样的时间就可能达到数十甚至上百毫秒,要是在传感器的忙循环里面检查音频缓冲,是不是也太混乱了点。哎,最好的办法或许是在时钟中断里检查传感器接受端引脚,然后计算时间与传感器值、再扔进滤波和迟滞触发,但是这点时间可能也很难改过来了。音频合成输出加上电容传感忙循环是什么魔鬼组合啊啊啊。
不过无论如何,可以先开始试试放一些采样进去。先在电脑上参考现成的弦乐采样,用朴素的合成器 Helm 搓出至少算是有点类似的音色,又照着常见的做法做了个鼓声,简单调了调,再写脚本把采样表打出来。
| 采样数值表 | gen_wavetable.lua(1.9 KiB) |
接着给 Arduino 的程序加上采样器。
template<int Length, const int16_t *Table> struct SampleSynth { int pos; SampleSynth() { pos = -1; } inline void start() { pos = 0; } inline int16_t sample() { if (pos < 0) return 0; int16_t result = pgm_read_word(&Table[pos]); // 见下 if (++pos == Length) pos = -1; return result; } };
然后贴上脚本生成的表,在时钟中断例程里控制循环播放与输出。
需要注意的是,由于数据量比较大,必须放入闪存(.text)而不能放在内存(.data);仅使用 const 是不够的,还需要额外指明 PROGMEM 修饰符(即 __attribute__((progmem))),将其保留在闪存中,而不加载进 RAM;如此一来指针的值即为闪存地址而非 RAM 地址,需要使用 pgm_read_*() 函数方能读取到实际数据。上一段程序中的 pgm_read_word() 调用即是读取双字节宽度的采样。
const PROGMEM int16_t kickTable[] = { /* ... */ }; const PROGMEM int16_t stringsTable[] = { /* ... */ }; SampleSynth<sizeof kickTable / sizeof kickTable[0], kickTable> synKick; SampleSynth<sizeof stringsTable / sizeof stringsTable[0], stringsTable> synStrings; int16_t nextSample = 0; ISR(TIMER1_COMPA_vect) { // 尽快输出上一个采样 McpDac.fastWriteA(nextSample); // 合成下一个采样 int16_t sample = 0; sample = sat_add(sample, synKick.sample()); sample = sat_add(sample, synStrings.sample()); uint16_t sample_i = (uint16_t) ((((int32_t)sample + (1L << 15)) * 120L + (1L << 15)) >> 16); nextSample = sample_i; // 每隔 2 秒从头播放一次 static int timerCount = 0, pinStatus = 0; if ((timerCount = ((timerCount + 1) % 8000)) == 0) { digitalWrite(13, (pinStatus ^= 1)); // synKick.start(); synStrings.start(); } }
上传,确实能发出声音。然而采样率与位深的限制比想象中大得多,实际的声音与想象中有很大差异。虽然友人说实际上还可以,但这样真是很难接近设计中的“自然”声响,低频的声音则更是完全听不见。
注:也许主要的原因正如前文所述,是末尾的滤波电容不够大的缘故。
无论如何,先与传感触发机制接起来试试。也就是每当触发互动时调用 synStrings.start()。然而事情的发展仍然出乎意料:传感器的读数变得非常混乱,噪声很大,即使用手触摸互动区域,也没法在 Plotter 上看出任何区别。CapacitiveSensor 库的一个讨论帖提到,数字信号会耦合到传感网络中。
这时已过了午夜。如此紧迫的时间下,目前的方案算是走到了绝路。考虑过使用两块 Arduino 通过 I²C 或 SPI 连接,一个负责传感读数、传递控制信号,另一个则负责发出声音,然而一方面以目前的知识水平并不清楚是否仍会存在耦合现象,另一方面元器件的数量与装置的尺寸都不足以支持在每个互动区域都如此放置两块 Arduino。
友人此时拿出之前一个机器人创意套件里的 MP3 模块。这个模块通过 USART 串口通信完成播放、暂停、音量等控制,而声音数据则是直接用 USB 连接电脑传输,像普通 U 盘一样把 MP3 文件复制进去即可。是个虽然极不优雅,却十分简单稳定的方案。两人决定放弃之前辛苦焊接的电路,只使用洞洞板上的电源与扬声器部分。
修改程序。MP3 模块自带一个程序库,直接调用即可。不过由于模块通信占用了 USART 串口,没法再打印调试,这为传感阈值校准带来了一些困难,因为之前的实验表明通过电脑 USB 接口与普通 USB 电源供电时读数的特性有所不同,似乎普通电源供电时噪音更大一些。不过无论如何,都比原本摇摇欲坠的方案要可控得多,既不用担心数据量与音质,也能保留清晰的读数。
注:读数特性不同也许是由于没有加稳压电容,因而没有排除电源噪声的影响?
约一小时后,程序与电路的修改均完成,在顶部的拍按区测试成功。
接下来空缺的任务便是补全声音。既然现在不必再牺牲音质,自然想追求尽可能理想的声音。从 Freesound 与网上的视频中找到了一部分音效,另外用 iPad 上的 GarageBand 做了一些弦乐声音。集齐声音后两人便回到宿舍,等待白天出发前去布展。
目前剩余的工作包括修改其余电路板的接线、上传声音数据、针对每个区域修改播放参数,以及最终校准阈值,这些都只能留到展览现场完成啦。希望一切顺利。
布展日
友人提前到达工作室完成所有电路板的重焊接,下午乘出租车出发前往场地。
场地距离学校约有一个半小时车程,在车上睡了一觉,便到达一个空旷的公园,一排排展位小棚散落在草木之间。这里的温度比市区要低,是个避暑的好地方。

连拖带拽把装置搬到展位上。小团队能准备的内容比较有限,不像有些展位那样能用各种物料装扮展位。不过能成功展出就很开心啦。

接着把元器件摊开,开始接线。首先把所有 Arduino 接上传感电极从玩具底部伸出的杜邦线,再把 MP3 模块插上电脑、复制文件,最后接上 Arduino。然后调整一下灵敏度阈值就可以完工了。
其中毛绒区、凸条区、斗状区三个区域需要按照互动时长作淡入淡出,之前每隔 2 ms 发送的音量控制指令产生的效果非常随机,怀疑指令之间有最短间隔限制,于是顺着程序库的指令序列上网搜索、找到模块内芯片的型号 WT2000B03,翻出数据手册,在上面找到这样一句:“发送每串命令之间的时间间隔不低于 300 ms。”不过实际上经过试验,50 ms 的间隔也可以维持正常工作。效果很不错。
| 音量控制测试 | Sound_Fluff.mp4(420 KiB, 00:08, 270x480) |
两人的晚饭是饺子,拍了张看上去十分寒酸的临时工伙食照片。

晚上园区临近关闭时总算完成了所有部分,设备搬动、拆开重新组装,也都可以正常运转。临走前还有展览工作人员前来围观。
| 完整程序 | FUNgi_0517.ino(9.1 KiB) |
收拾好展位,两人在公园里散了一会儿步。“感觉像是家里父母饭后会喜欢来的地方!”

感觉也会是个看星星的好地方呢。
辛苦啦!走咯。
